- 한국의
-
EnglishDeutschItaliaFrançais한국의русскийSvenskaNederlandespañolPortuguêspolski繁体中文SuomiGaeilgeSlovenskáSlovenijaČeštinaMelayuMagyarországHrvatskaDanskromânescIndonesiaΕλλάδαБългарски езикGalegolietuviųMaoriRepublika e ShqipërisëالعربيةአማርኛAzərbaycanEesti VabariikEuskeraБеларусьLëtzebuergeschAyitiAfrikaansBosnaíslenskaCambodiaမြန်မာМонголулсМакедонскиmalaɡasʲພາສາລາວKurdîსაქართველოIsiXhosaفارسیisiZuluPilipinoසිංහලTürk diliTiếng ViệtहिंदीТоҷикӣاردوภาษาไทยO'zbekKongeriketবাংলা ভাষারChicheŵaSamoa日本語SesothoCрпскиKiswahiliУкраїнаनेपालीעִבְרִיתپښتوКыргыз тилиҚазақшаCatalàCorsaLatviešuHausaગુજરાતીಕನ್ನಡkannaḍaमराठी
Xilinx FPGA 프로그래밍 및 Vivado 디자인 흐름 설명
목차

Xilinx FPGA 튜토리얼 탐색
FPGA 작업은 처음에는 소프트웨어보다 정신적으로 더 힘들게 느껴질 수 있습니다. 그 이유는 목표가 명령을 실행하는 것이 아니라 동시에 실행되는 하드웨어 구조를 설명하는 것이기 때문입니다. 동시성, 클럭 규칙, 리셋 동작 및 타이밍 보고서가 자신이 구축한 것과 일치하는지 여부에 대해 고민하게 됩니다. 사람들이 초기에 좌절감을 느끼는 것은 종종 노력이 부족해서가 아니라, 시도 사이에 너무 많은 이동 부품이 변경되기 때문이며 실패의 원인이 짜증 나게도 미끄럽기 때문입니다.
안정적인 진행 방법은 동일한 워크플로를 반복하여 실수가 두드러질 정도로 익숙해지도록 하는 것입니다. 책상에 잘 지원되는 Xilinx 보드를 하나 두고, 작은 HDL 디자인으로 시작하여 파형이 이해되는 때까지 시뮬레이션한 후, Vivado에서 합성과 구현을 실행하고, 장치를 프로그래밍하며, 실제 핀에서 동작을 확인하십시오. 이 과정이 반복적으로 보일 수 있지만, 문제의 원인이 디자인 코드, 제약 조건 또는 보드 구성에 의해 발생하는지에 대한 불확실성을 줄이는 데 도움이 되어 디버깅을 더 효율적으로 만듭니다.
일상적인 학습에서 곤란한 부분은 일반적으로 서로 강화하는 몇 가지 기술에 몰려 있습니다: Vivado의 흐름을 규칙적으로 사용하기, 기대하는 방식으로 매핑되는 합성 가능한 Verilog 작성하기, 신뢰할 수 있는 방법으로 시뮬레이션과 실제 보드 간의 불가피한 간극 디버깅하기. 각 빌드를 통제된 실험으로 간주하면, 변수를 하나 변경하고, 효과를 관찰하고, 본 것을 기록하게 되면, 추측하는 데 드는 시간이 줄어들고 신뢰할 수 있는 본능을 키우는 데 더 많은 시간을 할애하게 됩니다.
Vivado의 프로젝트 흐름을 시간이 지나도 안정적으로 유지하는 방법 사용
Vivado는 단순한 컴파일 버튼처럼 행동하기보다는 RTL을 보드의 전기적 및 타이밍 현실에 맞게 배치되고 라우팅된 디자인으로 변환하는 파이프라인처럼 행동합니다. 많은 초보자들은 때때로 힘든 경험을 통해, 많은 정확성이 HDL 외부에 존재한다는 것을 발견합니다: 제약 조건, 클럭 정의, I/O 표준 및 도구 설정은 하드웨어가 시뮬레이션이 약속한 대로 작동할지 여부를 조용히 결정할 수 있습니다.
깨끗한 흐름은 프로젝트 설정을 단순하고 반복 가능하게 유지함으로써 시작하여, 디자인이 개선된 것이 언제인지와 실수로 환경이 변경된 시점을 구분할 수 있도록 해야 합니다.
지원되는 보드 하나를 선택하고 직관적으로 재사용할 수 있을 만큼 오랫동안 그 보드에 머물러야 합니다. 훌륭한 문서화 및 참조 디자인이 있는 보드는 배경 불안감을 줄이는 경향이 있으며, 비공식 포럼 게시물을 찾지 않고도 핀 배치, 클럭 및 전원 가정을 교차 확인할 수 있습니다.
가시적인 결과를 빠르게 생성하는 상위 모듈부터 시작하십시오. 즉각적인 피드백은 클럭이 작동하고 핀이 올바르게 매핑되며 비트스트림이 생각하는 방식으로 생성되고 있음을 확인하는 데 도움이 됩니다.
관찰 가능한 최상위 수준의 동작 예:
• 깜박이는 LED
• UART 에코
• GPIO를 구동하는 카운터
실용적인 습관은 초기 단계에서 작은 최상위 템플릿을 표준화하는 것입니다. 예를 들어, 하나의 클락 입력, 이해할 수 있는 하나의 리셋 접근법, 그리고 작고 일관된 GPIO 번들을 유지하세요. 스캐폴딩이 프로젝트마다 동일하게 유지되면, 매번 기본 원리를 재유도하는 대신 새로운 논리에 집중할 수 있습니다. 이는 귀찮고 놀랍게도 오류가 발생하기 쉬운 작업처럼 느껴질 수 있습니다.
제약 조건은 FPGA 설계의 핵심 부분이지 최종 조정 단계가 아닙니다. RTL 설계가 올바르더라도 커다란 하드웨어 문제는 클락 제약 조건이 누락되거나 잘못되었거나, 핀이 잘못 할당되었거나, I/O 표준이 실제 보드 요구 사항과 일치하지 않을 때 발생합니다.
여러분을 정직하게 유지하는 구체적인 작업 흐름은 XDC에서 클락을 정의하고, 공급업체의 마스터 XDC를 참조하여 포트를 매핑한 다음, 보드 회로도에 대해 I/O 표준을 검증하는 것입니다. 이 과정은 처음에는 약간 관료적이라고 느껴질 수 있지만, 모호한 의심을 검증 가능한 사실로 대체하는 경향이 있습니다.
타이밍 클로저는 빠른 설계만을 위한 것이 아닙니다. 종이 위에서 느려 보이는 논리도 도구가 의도하지 않은 클락 관계를 추론하거나 비동기 신호가 무심코 처리될 경우 나쁜 동작을 할 수 있습니다. 초기 타이밍 보고서를 읽는 데 편안함을 느낀다면 설계가 커질 때 "이게 괜찮기를 바란다"는 불안한 감정을 줄일 수 있습니다.
Vivado는 항상 여러분의 설계에 대한 의견을 전달합니다; 고통스러운 점은 경고를 지나치기 쉬워서 콘솔에 이미 설명된 문제를 몇 시간 동안 디버깅하는 데 시간을 낭비하게 된다는 것입니다. 시간이 지나면서 더 빠르게 이동하는 사람들은 대개 모든 것이 괜찮다고 기대할 때마다 각 실행 후 보고서를 확인하는 차분한 습관을 기르는 사람들입니다.
모든 합성/구현 실행 후, 이러한 보고서 카테고리를 각자 체크리스트의 개별 항목으로 유지하세요:
• 타이밍 상태 및 주요 경로
• 기대치 대비 자원 활용 (LUT/FF/BRAM/DSP)
• 추론 결과 (RAM, DSP 블록 및 기타 의도된 구조에 대한)
경고가 첫 빌드 이후 계속 존재했다면, 이후의 가장 이상한 실패에서 계속 나타나는 경향이 있습니다. 경고는 특정 설계에 대해 무해하다고 설명할 수 있을 때까지 관심을 필요로 한다고 가정하는 생산적인 자세가 필요합니다.
FPGA 하드웨어에 깔끔하게 매핑되는 합성 가능한 Verilog 작성하기
HDL 작업은 앱 개발보다 회로 설계에 더 가깝고, 이는 감정적으로 충격적일 수 있습니다: 아름답게 시뮬레이션되면서도 느리거나, 크거나, 단순히 여러분이 생각했던 것과 다른 것으로 합성되는 유효한 Verilog를 작성할 수 있습니다. 목표는 FPGA가 예측 가능하게 구현할 수 있는 구조를 설명하는 것입니다: 플립플롭, LUT 논리, BRAM, DSP 블록 등으로, 동작과 타이밍이 여러분의 의도와 일치하도록 합니다.
매핑이 예측 가능하면, 디버깅은 도구와 논쟁하는 것처럼 느껴지지 않고 설계를 다듬는 것처럼 느껴집니다.
많은 초보자에게 편안한 기준선은 간단한 동기식 논리를 갖춘 단일 클락 도메인입니다. 순차적 상태에는 클락드 항상 블록을 사용하고, 조합 경로에는 연속 할당 (또는 적절하게 작성된 조합 블록)을 사용하세요. 패브릭에서 "클록 같은" 논리를 만드는 것은 특정 사례에서 작동할 수 있지만, 클락 게이팅, 라우팅 및 타이밍 함의를 이미 이해하지 않는다면 클락 도메인 위험을 초대하는 경향이 있습니다.
리셋 동작은 작은 선택이 놀라울 정도로 일관되지 않은 보드 결과를 초래할 수 있는 또 다른 곳입니다. 비동기 리셋은 유용할 수 있지만, 신호 비활성 위험 또는 보드 레벨 전원 켜짐의 차이에 민감성을 발생시킬 수 있습니다. 많은 FPGA 설계는 비동기 발생과 동기적 해제를 사용하는 완전 동기식 리셋을 사용하여 부팅 테스트 중 일관되지 않은 시작 동작을 줄이는 데 도움이 됩니다.
FPGA 논리는 자연스럽게 파이프라인 및 병렬 구조에 의존합니다. 초보자가 흔히 실망하는 점은 소프트웨어처럼 단계별로 실행되기를 기대하다가 모든 것이 한 번에 발생할 때 혼란스러워한다는 것입니다. 더 유용한 관점은 주어진 블록에 대해 중요하게 여기는 사항을 결정한 다음, 그 결과를 위해 명시적으로 설계하는 것입니다.
성능 및 매핑을 위한 단일 라인 설계 관점:
• 처리량 (클록당 항목 수)
• 대기 시간 (입력에서 출력까지의 사이클)
• 자원 매핑 선호도 (LUT 대 BRAM 대 DSP)
예를 들어, 곱셈-누적은 DSP 슬라이스를 깔끔하게 추론할 수 있지만, 사소한 코딩 스타일 변경으로 도구가 LUT 기반 산술로 기울어질 수 있습니다. 활용도에서 놀랄 경우, 잠시 멈추고 약간 불편한 질문을 해보는 것이 종종 가치가 있습니다: 실제로 의도한 하드웨어 구조를 설명했나요, 아니면 더 많은 자원을 소모하는 기능적으로 동등한 무언가를 설명했나요?
시뮬레이션은 실제 하드웨어가 구현할 수 없는 구조를 기꺼이 수용합니다. 합성 가능한 경계를 명확하게 유지하면 잘못된 자신감을 줄이고 시뮬레이션 결과를 보드에 더 쉽게 적용할 수 있습니다.
그룹화된 패턴을 한 줄로 유지하여 빠른 참조:
• 신뢰할 수 있는 논리에서 지연(#)을 피하십시오.
• 장치/도구 동작을 확인하지 않은 상태에서 초기화에 의존하지 마십시오.
• 불완전한 조합 할당으로 인해 의도하지 않은 래치를 주의하십시오.
• 클락 도메인 크로싱에 적절한 동기화를 사용하십시오.
작은 자기 검증 테스트벤치를 작성하는 습관은 보통 보상을 제공합니다. 이 테스트는 리셋 동작, 카운터 롤오버, 핸드쉐이크 프로토콜 및 코너 조건 등 감정적으로 손쉽게 넘길 수 있는 가정을 검증합니다. 프로젝트가 커짐에 따라 이러한 테스트는 추가 작업처럼 느껴지지 않고 모든 것을 다시 고려하지 않도록 해주는 역할을 합니다.
시뮬레이션 및 온칩 가시성(ILA)으로 체계적으로 디버깅합니다.
뛰어난 시뮬레이션도 보드의 올바른 동작을 보장하지 않습니다. 실제 하드웨어는 클락 지터, I/O 지연, 알 수 없는 초기 상태 및 클락 엣지에 정렬되지 않은 비동기 입력을 가져옵니다. 가장 빠른 디버거는 대개 무작위 편집을 하는 것이 아니라 구조화된 관찰로 문제를 좁히고, 그들의 판단을 바꾼 증거를 설명할 수 있는 사람들입니다.
강력한 테스트벤치는 많은 사이클 동안 동작을 체크하며 불편한 시나리오를 피하지 않습니다. 현실적인 자극을 모델링하면, 시뮬레이션은 신호가 토글되는 것을 보고 그게 무언가를 의미하길 바라는 공간이 아니라 자신감을 쌓는 장소가 됩니다.
취약한 논리를 드러내는 현실적인 자극:
• 버튼 바운스
• UART 프레이밍 오류
• 스트리밍 인터페이스의 백프레셔
• 어색한 타이밍의 리셋 시퀀스
잘못된 종류의 수정을 추적하지 않도록 버그를 두 개의 범주로 나누는 것도 도움이 됩니다:
• 기능적 버그: RTL의 논리가 잘못됨
• 통합 버그: RTL은 괜찮지만, 클락/리셋/제약/I/O 가정이 틀림
시뮬레이션은 기능적 버그를 찾아내는 데 탁월합니다. 보드 테스트는 당신이 믿고 싶지 않은 통합 버그를 드러내는 방식이 있습니다.
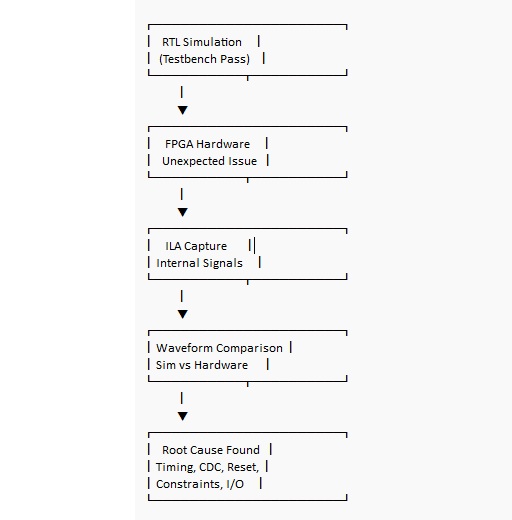
하드웨어 동작이 당신의 테스트벤치와 일치하지 않을 때, 통합 논리 분석기(ILA)는 추측을 학습할 수 있는 추적으로 대체하는 가장 직접적인 방법입니다. 설계 내부에서 결정과 경계를 나타내는 신호를 프로브한 다음, 상황이 다르게 전환되는 순간을 캡처하여 예상되는 시뮬레이션 웨이브폼과 비교합니다.
높은 가치의 프로브가 되는 경향이 있는 신호:
• FSM 상태 인코딩
• 유효/준비 핸드쉐이크
• FIFO 풀/엠프티 플래그
• 리셋 동기화기 출력
실용적인 워크플로우는 더 적은 프로브와 더 넓은 캡처 윈도우로 시작하는 것입니다. 실패가 발생하는 위치를 배우면 트리거를 조이고 세부 사항을 추가할 수 있습니다. 과도한 계측은 타이밍 여유를 줄이고 빌드를 복잡하게 만들 수 있으므로, ILA 삽입을 단순히 만일을 대비한 것이 아니라 집중된 측정 단계로 취급하는 것이 더 건강한 접근입니다.
시뮬레이션이 결함이 없는 것처럼 보이고 보드가 불안정한 경우가 가장 교육적인 실패 중 일부입니다. 그 불일치는 실망감을 줄 수 있지만, FPGA 직관이 더 날카로워지는 곳이기도 합니다. 해결책은 주로 클락, 제약 또는 신호 위생에서 찾아지며 알고리즘 내지는 아닙니다.
시뮬레이션/보드 불일치의 일반적인 원인:
• 누락되거나 잘못된 클락 제약
• 비동기 입력으로 인한 메타 안정성
• 칩 전반에 걸친 리셋 해제 타이밍 변동
• 여러 클락 도메인 간 CDC 문제
• 초기 조건의 차이
타이밍과 가시성을 고유하게 설계에 통합된 속성으로 취급하는 관점은 학습을 가속화하는 경향이 있습니다. 작은 프로젝트에서 클락을 명시적으로 정의하고, I/O를 제약하고, 크로싱을 동기화하며, 내부 신호를 측정할 수 있도록 노출하면, 작동을 기대하는 데 적게 시간을 쓰고, 통제 가능하고 설명 가능한 개선을 만드는 데 더 많은 시간을 쓸 수 있습니다. 이러한 사고방식은 깜빡이는 LED에서 더 큰 파이프라인, 인터페이스 및 동일한 장치의 임베디드 시스템으로 자연스럽게 확장됩니다.
Xilinx (AMD) 대 Altera (Intel) FPG
Xilinx (AMD)와 Intel (Altera)는 모두 종이상 비교 가능한 FPGA 계열을 출하하며, 빠른 데이터시트를 스캔한 후 자신감을 느끼기 쉽습니다. 그러나 기분은 나중에 일상적인 엔지니어링 현실이 속도를 결정하기 시작할 때 변하는 경향이 있습니다: 정확한 장치 및 속도 등급에서 도구의 동작, 당신이 사용할 수 있다고 가정한 IP가 실제로 라이센스 가능 여부, 참조 설계가 진정으로 당신의 클락과 리셋에 맞는지, 설계가 생산 등급이 되었을 때 타이밍 클로저가 안정적으로 유지되는지 여부.
FPGA를 전달 시스템, 장치 + 도구 + IP + 보드 + 문서 + 장기 유지 관리로 취급할 때 선택 프로세스는 더 나은 결과를 보입니다. 여기서 팀은 동력을 얻거나(그리고 잠을 자거나) 조용히 일정에 대한 불안을 쌓아갑니다.
| 기능 |
자일링스 (AMD) |
인텔 (알테라) |
| 시장 위치 |
역사적으로 시장의 선두주자이며, 광범위한 제품 포트폴리오와 새로운 기술의 최초 출시로 알려져 있습니다. |
강력한 경쟁자로, 특히 데이터 센터 및 네트워킹 애플리케이션에서 강력하며, 인텔의 생산 능력을 활용합니다. |
| 코어 아키텍처 |
논리는 주로 6-input 룩업 테이블(LUT)에 기반하여 높은 세분화와 유연성을 제공합니다. |
더 복잡한 어댑티브 로직 모듈(ALM)을 사용하며, 이는 더 큰 LUT로 구성될 수 있어 특정 설계에 대해 논리 밀도를 향상시킬 수 있습니다. |
| 소프트웨어 스위트 |
비바도 디자인 스위트 및 비티스 통합 소프트웨어 플랫폼. 경험이 있는 개발자들에게 사용자 친화적인 인터페이스로 자주 칭찬받습니다. |
쿼터스 프라임 디자인 스위트. 일부 사용자는 초보자에게 더 직관적인 GUI를 제공하며, 특정 시나리오에서는 더 빠른 컴파일 시간을 주로 알고 있습니다. |
| 하이엔드 패밀리 |
벨사 ACAPs (어댑티브 컴퓨트 가속 플랫폼), 스칼라, 적응형 및 지능형 엔진 결합. |
애질렉스 FPGA는 높은 성능과 전력 효율성으로 알려져 있으며, 일부 벤치마크에서는 성능 대비 전력의 차이를 보여줍니다. |
| 생태계 초점 |
Zynq 패밀리에서 볼 수 있듯이 프로세서와 FPGA 통합에 강한 초점을 맞추고 있습니다. 애플리케이션 개발에 인기가 있습니다. |
시스템 온 칩 설계 및 산업 응용에 적합하며, 네트워킹 및 RF를 위한 강력한 IP 포트폴리오를 갖추고 있습니다. |
브랜드 기대감이 아닌 검증 가능한 제약 조건을 사용하여 선택 정의
이전 프로젝트의 인상보다는 일찍 테스트할 수 있는 요구사항으로 시작하세요. 목표는 "10주차의 놀라움"을 줄이는 것이며, 이는 좌절과 재작업이 쌓일 수 있는 곳입니다.
제약 조건 체크리스트:
• 논리 자원: LUT/ALM, 레지스터, 라우팅 가용성 및 예상 활용 한도
• DSP 자원: 블록 수, 정밀도 모드, 프리 애더, 캐스케이드/토폴로지 옵션 및 수학 커널의 매핑 동작
• 온칩 메모리: BRAM/URAM (또는 M20K 동등물), 총 용량, 포트 모드, 클럭당 대역폭 및 경쟁 패턴
• 고속 I/O: SERDES 클래스, 레인 수, 최대 라인 속도, 참조 클럭 옵션 및 사용 사례에 따른 프로토콜 지원
• 외부 메모리: DDR3/DDR4/LPDDR 변형, 컨트롤러 성숙도, 보정 동작 및 보드 수준 SI 여유 가정
• 지연 및 결정론: 종단 간 목표, 단계별 예산, 지터 허용 오차 및 CDC 전략(리셋이 도메인을 넘는 방법 포함)
• 전력/열 범위: 최악의 경우 스위칭 추정치, 트랜시버 전력 모드, 히트싱크 가정 및 주변 온도 범위
실제 FPGA 프로젝트에서는 장치 내에 적합하다고 해서 신뢰할 수 있는 고속 작동이 보장되지 않음을 종종 보여줍니다. 70-80% 활용률에서 수용 가능한 것으로 보이는 설계들은 디버그 논리, CDC 보호, FIFO, 오류 처리 및 실제 작동에 필요한 타이밍 여유를 추가하면 불안정해질 수 있습니다.
팀이 라우팅 혼잡으로 일주일을 잃은 적이 있다면, 하나의 장치 크기를 늘리는 것이 이해하기 쉽습니다. 비용 무역은 일반적으로 선형적이지 않으며, 조금 더 큰 부품이 더 차분한 타이밍, 반복적인 도구 회수 및 늦은 시간의 재구성을 줄일 수 있습니다.
도구 흐름을 없앨 수 없는 요구로 취급하세요
도구 흐름은 계획이 탄탄해 보이는 것과 계획이 계속 미끄러지는 것 사이의 숨겨진 구분자입니다. 사람들은 빌드에 몇 시간이 걸리고 실패 모드가 모호할 때 느리고 예측할 수 없는 반복에서 소모되는 정서적 밴드폭을 과소평가하는 경우가 많습니다.
도구 흐름 평가 체크리스트:
• 반복 속도: CI 하드웨어에서 합성 + 배치/라우팅 + 비트스트림 시간, 공급업체 데모 머신이 아닌
• 타이밍 종료 동작: QoR 추세, 시드 간 안정성 및 작은 제약 변화에 대한 민감도
• 제약 및 관측성: SDC/XDC 명확성, 클럭 모델링 정확성, 잘못된 경로/다중 사이클 처리 및 얼마나 디버그 가능한 위반인지
• 디버그 계측: 로직 분석기 삽입 흐름, 프로브 유연성, 트리거 깊이 및 신호 관찰을 위해 얼마나 자주 다시 컴파일해야 하는지
• 환경 적합성: 지원되는 OS 버전, 헤드리스 빌드, 라이선스 마찰 및 팀의 워크플로우와 얼마나 잘 맞는지
• CI/VCS 친화성: 재생산성, 결정론적 출력(도구가 허용하는 만큼), 스크립팅 가능성 및 업그레이드 어려움
의사 결정 전에 대표적인 무언가(장난감이 아님)에 대해 타이밍 종료 시험을 진행하세요. 실제 클럭, 최소한 하나의 외부 메모리 인터페이스 및 최소한 하나의 고속 I/O 블록을 포함하세요. 추적할 내용:
• 반복당 벽시계 컴파일 시간
• 몇 개의 시드 간 여유 안정성
• 엔지니어가 부족한 지식 없이 첫 세 가지 타이밍 문제를 얼마나 빨리 진단할 수 있는지
그 실험은 기능 체크리스트에서는 얻을 수 없는 일종의 명료함을 생성하는 경향이 있다. 또한 팀이 통합 단계에서 안정감을 느낄지 아니면 지속적으로 긴장할지를 드러낸다.
IP 가용성 및 라이선스: 일정이 일반적으로 빡빡해지는 곳
원시 FPGA 리소스가 비슷해 보일 때에도, 일정은 종종 IP 현실에 달려 있다. 이 지점에서 팀은 예기치 않게 실망할 수 있다: 코어는 존재하지만 라이선스 모델, 통합 작업 또는 문서 품질이 이를 느린 진행으로 바꿔 놓는다.
IP 및 라이선스 체크리스트:
• 프로토콜 스택: PCIe, 이더넷 MAC/PCS, JESD204, DDR 컨트롤러, 및 의존하는 모든 니치 인터페이스
• 라이선스 조건: 노드 잠금형 대 플로팅, 기능 추가, 빌드 서버/CI에 대한 영향, 및 모든 런타임 또는 배포 제약
• 참조 설계: 레인 수, 클록 계획, 리셋 순서, DMA 아키텍처, 및 시스템 경계와 일치 여부
• 지원 수명: 장기 유지보수 기대치, 패치 주기, 및 문제의 우선 순위 지정 방법
팀이 어려운 방법으로 배우는 미세한 점: 이용 가능한 IP는 바로 사용할 수 있는 IP와 다르다. 실험실 데모는 지연 시간, 버퍼링, 및 클록 목표를 달성하기 위해 필요한 통합 작업을 숨길 수 있다. 검증을 위한 계획 시간을 편성하고, 직접적인 문서와 검증된 좋은 예제가 있는 IP를 선호하는 것이 나중에 스트레스 수준을 줄이는 경우가 많지만, 초기 평가는 더 느리게 느껴질 수 있다.
보드 생태계, 기동 위험, 및 알려진 좋은 플랫폼의 편안함
FPGA 선택은 보드 현실에 연결된다. 기동 중에는 시간은 RTL이 아니라 플랫폼 불확실성으로 소멸하는 경향이 있다: 하나의 클록 제약을 놓치거나, 명확하지 않은 리셋 의존성, 또는 특정 온도에서만 미세한 송수신 채널이 있다.
보드 및 플랫폼 체크리스트
• 평가 보드 및 참조 플랫폼: 가용성, 개정 안정성, 및 현장에서 널리 사용되는 설계 여부
• 전원 공급 안내: PDN 목표, 디커플링 접근법, 레일 시퀀싱 기대치, 및 허용 오차 스택 가정
• 고속 레이아웃 참조: 송수신기 라우팅 안내, 규정 준수 노트, 및 검증된 스택업
• 디버그 접근: JTAG 안정성, 부팅/구성 모드, 구성 플래시 지원, 및 레일/클록에 대한 가시성
• 지원 반응성: 공급업체 채널, 커뮤니티 신호 대 잡음 비율, 및 도구/IP 문제의 처리 시간
검증된 참조 설계가 있는 널리 채택된 플랫폼을 사용하면 시스템 기동을 보다 구조적이고 예측 가능하게 만들 수 있다. 이러한 접근은 문제 해결이 광범위한 불확실성에서 단계별 측정 가능한 검증으로 이동하도록 도와주며, 개발 효율성을 향상시킨다.
타이밍 종료
타이밍 종료는 공급업체 간의 차이가 구체화되는 지점으로, 특히 사용률이 상승하고 여러 클록 도메인이 상호작용할 때 더욱 그러하다. 이 단계에서 설계 진행은 안정적이고 예측 가능할 수 있지만, 작은 변화가 큰 타이밍 변동을 초래할 때 어려워질 수 있다.
• 혼잡 증가: 사용률이 상승함에 따라 라우팅 압력이 어떻게 증가하는지, 그리고 어디서 급증하기 시작하는지
• Fmax 예측 가능성: 중간 제약이 얼마나 자주 원하는 수준에 근접하게 해주는지, 또는 중대한 수동 조정이 필요한지
• 보고 품질: 타이밍 보고서가 실행 가능한 수정을 가리키는지, 단순히 긴 위반 목록만 포함하는지
• 견고성: PVT 변동과 구현 시드 전반에 걸친 동작
일반적으로 밀도에 따라 종료 노력이 비선형적으로 증가한다고 가정하는 것이 더 안전하다. 특정 임계값을 넘으면 사소한 RTL 조정이 여유를 건강한 상태에서 취약한 상태로 바꿀 수 있다. 아키텍처 여유, 파이프 라이닝, 선택적인 바닥 설계, 및 숨 쉴 공간이 있는 장치 선택은 종종 아무도 유지하고 싶지 않은 극단적인 제약 조정을 초월한다.
정확한 부품 비교
사양은 세대별 및 단일 패밀리 내에서 변동한다. 유사한 이름을 가진 두 부품은 포장, 속도 등급, 도구 성숙도가 고려되었을 때 계획을 방해할 만큼 다르게 동작할 수 있다.
• 속도 등급: 달성 가능한 Fmax, 송수신기 여유 동작, 및 타이밍 모델 차이
• 패키지: I/O 수, 은행 배치, SI 영향, 열 동작, 및 조립 제약
• SKU 기능 한계: 사용 중지된 블록, 감소된 송수신기 능력, 메모리 비율, 또는 특정 변형의 프로토콜 제한
• 도구 성숙도: 장치 지원 수준, 출시 주기, 및 팀이 안정적인 도구 버전에서 표준화할 수 있는지 여부
실용적인 비교 방법:
• 실제 클록 및 인터페이스에 매핑된 공급업체 타이밍 모델
• 현실적인 토글 비율, 듀티 사이클, 및 송수신기 설정을 사용한 전력 추정
• 보드 요구 사항 및 커넥터 맵에 맞춘 핀 배치/은행 제약
• 조직이 제품 수명 동안 사용할 수 있는 도구 버전(지속적 통합 포함)
스트레스가 심할 때 버티는 경향이 있는 의사 결정 프레임워크
일정 압박이 증가할 때, 측정 기반의 프레임워크는 후회-driven pivot을 피하는 데 도움이 됩니다. 또한, 결정이 낙관론보다는 관찰된 결과에 연결된 서류 흔적을 가지고 있기 때문에 팀이 더 안정감을 느끼도록 도와줍니다.
균형 잡힌 선택 순서:
1) 측정 가능한 요구사항 고정: 자원, I/O, 메모리, 지연 시간 및 전력/열 예산.
2) 각 후보의 가장 어려운 하위 시스템을 프로토타입합니다: 타이밍 동작 + 디버그 워크플로우 + 빌드/CI 루프.
3) 마케팅 요약이 아닌 통합 계획에 대한 IP 성숙도 및 라이센스를 평가합니다.
4) 최소 요구 사항을 겨우 충족하는 옵션이 아니라 여유가 있고 가장 예측 가능한 반복 루프를 가진 옵션을 선택합니다.
핵심 포인트는 최고의 FPGA는 화려한 헤드라인 숫자를 가진 것이 드물다는 것입니다. 팀은 보통 플랫폼이 제품 수명 동안 안정적인 수렴, 반복 가능한 빌드 및 유지 관리 가능한 솔루션을 지원할 때 더 빠르고, 덜 의심하게 움직입니다.
핵심 툴체인

Vivado의 FPGA 워크플로우에서의 역할
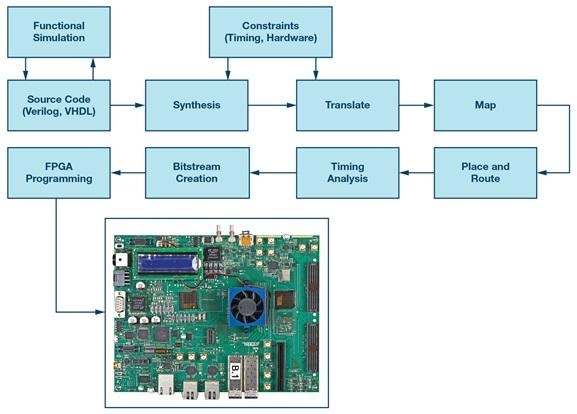
Vivado는 화려해서가 아니라 모든 가정이 도구 현실에 대해 최종적으로 테스트되는 곳이기 때문에 Xilinx FPGA 프로젝트의 운영 허브가 되는 경향이 있습니다. HDL 및 제약 조건을 수집하고, 넷리스트를 생성하며, 타이밍 및 물리적 설계 규칙을 균형 있게 배치하고 라우팅을 수행한 다음 장치를 프로그래밍하는 비트스트림을 생성합니다.
Vivado를 이해하는 실용적인 방법은 그것을 두 개의 연결된 시스템으로 보는 것입니다: RTL-넷리스트 변환 시스템과 물리적 구현 최적화기. 이는 제약이 불완전할 때, 클락 정의가 부정확할 때, 또는 설계 구조가 라우팅 및 타이밍의 어려움을 초래할 때 논리적으로 올바른 RTL도 여전히 불안정하거나 일관되지 않은 결과를 생성할 수 있는 이유를 설명합니다.
대부분의 프로젝트는 장치 패밀리 및 흐름 스타일에 따라 세부 사항이 다르더라도 익숙한 파이프라인을 따릅니다.
• 합성: RTL을 게이트 레벨 표현으로 변환하고 장치 특정 구조를 추론합니다.
• 구현: 물리적 제약 조건 하에 배치, 라우팅 및 타이밍 주도 최적화를 수행합니다.
• 비트스트림 생성: 구성 이미지를 방출하고 구현된 결과를 제약 조건 및 도구 규칙과 교차 확인합니다.
일정은 비트스트림이 한 번 생성될 때가 아니라 팀이 비트스트림이 신뢰할 수 있는 출력처럼 작동해야 할 때 긴장하게 되는 경향이 있습니다: 재빌드 간 유사한 결과, 목표 속도 등급에서 살아남는 타이밍 여유, 및 기능 수정의 작은 RTL 편집 시 안정성. 어제 만들어진 것이 더 이상 위안을 주지 않는 지점입니다.
시간이 경과할수록 더 빠르게 움직이는 팀은 보통 보고서를 문서 작업으로 취급하는 것을 중단하고 이를 엔지니어링 증거처럼 다루기 시작합니다. 빌드 산출물이 일관되게 수집되면 설계 논의가 덜 감정적이고 보다 구체적으로 변화하여 마감일이 가까울 때 안도감을 줍니다.
• 합성/구현 보고서: 활용도, 추론된 원시 요소, 경고 및 구조적 요약.
• 타이밍 출력: WNS/TNS, 실패하는 끝점, 상세 경로 및 클락 상호 작용 요약.
• XDC 제약 조건: 클락, I/O 규칙, 예외 및 물리적 핀 할당.
• 구현된 체크포인트(DCP): 빠른 반복 및 제어된 실험을 지원하는 재현 가능한 스냅샷.
실제 작업에서 나타나는 패턴은 깔끔하고 내부적으로 일관된 보고서 세트가 종종 한 개의 녹색 “PASS” 배너보다 더 원활한 진행을 예측한다는 것입니다. 배너는 취약성을 숨길 수 있지만, 보고서는 일반적으로 그렇지 않습니다.
설치 및 환경 설정
GUI를 단순히 실행하는 설치는 기념하기 쉬우나 나중에 후회할 수 있습니다. 팀이 신뢰하는 설정은 좋은 의미의 지루함이 있습니다: 자동화 하에서 동일하게 작동하며, 기계 간에 일관되며, 도구 업데이트 후에 당신을 놀라게 하지 않습니다.
장치 목표와 일치하는 Vivado ML 에디션을 선택한 다음, 실제로 빌드할 계획인 장치 패밀리만 활성화합니다. 이렇게 하면 디스크 사용량과 인덱싱 시간이 줄어들고, 오후를 낭비할 수 있는 우연한 교차 패밀리 구성 실수의 가능성도 줄어듭니다.
다중 보드 개발 팀에서는 각 프로젝트에 대한 지원되는 장치 목록을 명확히 유지하는 것이 어떤 도구나 부품이 설치되었는지에 의존하는 것보다 개발을 더 잘 통제하고 일관되게 유지하는 데 도움이 됩니다.
Vivado 출력은 배치, 라우팅 및 타이밍 알고리즘이 발전하고 버그가 수정(또는 다른 버그로 대체)되기 때문에 버전 간에 변경될 수 있습니다. 많은 팀이 릴리스 브랜치당 하나의 도구 버전을 고정하고 계획된 단계로 업그레이드하여 더 차분한 빌드를 얻습니다.
새로운 버전을 시도할 때, 팀은 새로운 기준으로 채택하기 전에 도구의 건강 상태에 대한 실질적인 신호인 타이밍 여유, 활용 변화, 경고 델타 및 새로운 제약 조건 커버리지 메시지를 비교하는 경우가 많습니다. 이러한 비교를 수행하는 데 소요되는 시간은 일반적으로 사이클이 끝날 무렵에 타이밍이 이유 없이 갑자기 나빠졌는지에 대해 논쟁하는 것보다 더 쉽습니다.
명령줄 빌드, CI 시스템 및 공유 빌드 서버의 경우 개발 환경은 개별 머신 구성에 의존하기보다는 모든 시스템에서 일관되게 작동해야 합니다.
• 설정 스크립트: 경로, 라이브러리 및 런타임 종속성이 일관되게 해결되도록 올바른 도구 설정을 소스합니다.
• Tcl 기반 흐름: 반복 가능한 실행, 일관된 보고 및 CI 통합을 위해 스크립트화된 빌드를 선호합니다.
• 빌드 인터페이스 규율: 입력과 출력을 안정적으로 유지하여 변경 사항이 의도적이고 검토 가능하도록 합니다.
일반적인 개발 워크플로는 먼저 디자인을 검증하기 위해 안정적인 GUI 빌드를 완료한 다음 GUI 설정, 캐시된 데이터 또는 개발 머신 간 차이에 의존하지 않는 Tcl 기반 흐름으로 전환하는 것입니다.
진단처럼 읽고 싶은 보고서
대부분의 디자인 실패 순간은 도구가 믿는 것에 대한 이야기로 보고서를 읽으면 오랫동안 신비롭지 않습니다. 경고, 제약 조건 커버리지 및 타이밍 경로는 실패 모드를 명확하게 문서화하는 경향이 있지만, 항상 가장 친근한 순서로 나타나지는 않습니다.
팀은 Vivado 출력을 매일 피드백 루프로 취급할 때 가장 빠르게 개선됩니다. 빌드가 중단될 때만 여는 것이 아닙니다.
이러한 보고서는 의도 드리프트가 처음으로 가시화되는 곳이며, 이는 이상하게도 안심이 될 수 있습니다: 적어도 문제가 구체적입니다.
• 자원 활용: LUT, FF, BRAM, DSP, URAM 대 장치 한계 및 여유.
• 추론 검사: 예상치 못한 RAM 스타일, 누락된 DSP 추론, 놀라운 원시 매핑.
• 구조적 위험 신호: 높은 팬아웃 넷, 넓은 다중화, 긴 조합 체인.
• 경고: 래치 추론, 불완전한 민감도 처리, 연결되지 않거나 잘린 논리.
래치 추론 및 의도하지 않은 긴 조합 경로는 실제로 자주 나타납니다. 도구는 이를 불만 없이 구현하며, 이후 타이밍이 비정상적 방식으로 협력하지 않으면 기만적으로 느껴질 수 있습니다. 경로 보고서를 읽기 전까지는 무작위처럼 보입니다.
타이밍 클로저는 팀이 도구가 최적화하는 것이 무엇인지, 그리고 특정 타협을 선택하는 이유를 알 때 덜 스트레스를 받습니다.
• 여유 신호: WNS는 최악의 단일 위반; TNS는 전체 위반의 분포입니다.
• 경로 분해: 지연이 축적되는 곳(논리 깊이, 라우팅, 클로킹 또는 제약 가정).
• 클록 모델링: 경로가 의도대로 분석되는지, 무시되는지, 잘못 그룹화되는지 여부.
경험이 많은 팀이 내면화하는 미묘한 교훈 중 하나는 타이밍 문제는 종종 제약 모델링 문제이기 먼저 하고 RTL 문제는 두 번째라는 것입니다. 클록 모델이 잘못되면 잘못된 끝점을 최적화하는 데 며칠이 걸릴 수 있으며, 여전히 도구가 듣지 않는 것처럼 느껴질 수 있습니다.
제약 공백은 반복적인 범죄자이며, 부분적으로는 프로젝트가 많이 진행될 때까지 잘 보이지 않기 때문입니다.
• 클록 정의 공백: 누락되거나 잘못된 기본 클록.
• 생성된 클록 공백: 나눠진/곱해진/전달된 클록이 선언되지 않아 도구가 추측해야 합니다.
• I/O 정의 공백: 누락된 I/O 제약 조건이 낙관적인 가정을 초래하고 이후 보드 수준의 놀라움으로 이어집니다.
• 예외 남용: 누락된 예외 또는 신뢰할 수 없을 정도로 너무 광범위한 예외.
실용적인 습관은 XDC를 패치 파일이 아닌 살아있는 사양으로 취급하는 것입니다. 예외가 도입되면 더 나은 수면을 취하는 팀은 이를 좁고, 설명이 붙어 있으며, 실제 타이밍 관계에 연결하여 사용하여 검토가 필요한 위반을 조용히 처리하려고 하지 않습니다.
XDC 제약 전략
XDC 파일은 디자인 의도를 명시적으로 만드는 곳입니다. 약간 잘못되면 결과적인 타이밍 행동은 도구가 완벽하게 결정론적임에도 불구하고 혼란스러워 보일 수 있습니다.
클록을 명시적으로 정의한 다음 도구가 예상한 대로 이를 전파했는지 확인합니다. 클록 모델 문제는 종종 더 깊은 구조적 타이밍 문제보다 수정하기 더 쉬우므로 타이밍 분석 및 디버깅 중에 해결하기 간단합니다.
• 기본 클록: 핀 또는 MMCM/PLL 출력에서 정의됩니다.
• 생성된 클록: 나눠진, 곱해진 또는 전달된 도메인에 대해 정의됩니다.
• 비동기 관계: 클록 그룹 또는 명시적 관계를 통해 선언됩니다.
실제 보드에서는 하나의 누락된 생성 클록이 며칠이 걸리는 잘못된 타이밍 그림을 생성할 수 있으며, 특히 도구가 함께 분석될 의도가 없었던 끝점을 최적화할 때 더욱 그렇습니다.
I/O 제약은 도구가 사용하는 전기 및 타이밍 가정을 형성하며, 이는 실험실 성공이 “시스템 성공”으로 이어질지를 조용히 결정할 수 있습니다.
• 전기 표준: 보드 설계와 일치하는 I/O 표준 및 전압.
• 핀 배치 규칙: 매핑이 안정화되면 핀 위치를 잠가서 변화가 없도록 합니다.
• 인터페이스 타이밍: 도구의 기본값이 아닌 외부 장치를 반영하는 입력/출력 지연.
익숙한 후기 단계의 실망감은: 빌드에서 타이밍을 충족했지만, 인터페이스가 실제 트래픽 하에서 실패한다는 것입니다. 이러한 결과는 종종 보드와 외부 장치의 타이밍 예산에 맞게 업데이트되지 않은 기본 I/O 가정으로 거슬러 올라갑니다.
예외는 의도를 명확히 할 수 있지만, 원래의 정당성을 넘어 생존할 경우, 미약한 진전의 환상을 만들어 낼 수도 있습니다.
• 거짓 경로: 경로가 실제로 기능적 타이밍의 일부가 아닐 때만 사용됩니다.
• 다중 주기 경로: 캡처 관계가 진짜로 여러 주기를 가로지를 때만 사용되며 문서화되어야 합니다.
• 예외 위생: 집합을 작게 유지하고, 주요 RTL/파이프라인 변경 후에 검토하며, 오래된 항목은 퇴출시킵니다.
가장 비싼 타이밍 버그 중 일부는 한때 정확했던 예외에서 발생하며, 이후 파이프라인 변경 후 조용히 부정확해집니다. 도구는 불만 없이 준수할 것이며, 이는 이 실패 모드가 그렇게 불쾌한 이유입니다.
전형적인 실패 패턴 및 이를 효율적으로 해결하는 방법
특정 문제는 프로젝트에 따라 반복 발생하며, 응용 프로그램이 네트워킹, 비전, 제어 또는 가속화와 관계없이 말입니다. 패턴을 조기에 인식하는 것은 디버깅의 감정적 부담을 줄이는 경향이 있으며, 팀은 “이런 일이 왜 일어나는가”에서 “어떤 플레이북이 적용되는가”로 이동할 수 있습니다.
이 상황은 종종 도구가 고집스럽다는 느낌이 들지만, 근본 원인은 대개 추적 가능합니다.
• 조합 깊이: 누락된 파이프라인 또는 불충분한 파이프라인으로 인해 발생한 긴 경로.
• 팬 아웃 압력: 복제, 버퍼링 또는 구조 변화로 이익을 얻을 수 있는 높은 팬 아웃 제어 네트.
• 제약 모델링: 분석되어야 할 것을 잘못 특성화하는 클록 정의나 관계.
잘 작동하는 경향이 있는 시퀀스는: 타이밍 모델(클록 및 관계)을 검증하고, 최악의 실패 엔드포인트에 우선 집중한 다음, 경로 증거가 뒷받침될 경우에만 아키텍처 변경으로 넓혀가면 됩니다.
이것은 FPGA 작업에서 가장 사기를 꺾는 경험 중 하나이며, 주로 현실이 불공평하게 느껴지기 때문입니다. 일반적으로는 시뮬레이션이 동일한 실패 모드를 스트레스 테스트하지 않았던 것입니다.
• CDC/초기화 동작: 초기화 순서와 클록 도메인 크로싱이 시뮬레이션에서 거의 현실적으로 시행되지 않습니다.
• I/O 가정: 변별력이 없는 또는 잘못 제약된 I/O가 미미한 실제 인터페이스를 생성합니다.
• 초기화 동작: 장치의 전원 켜기 동작에 깔끔하게 매핑되지 않는 초기 값에 대한 의존성.
안정성이 향상된 팀은 설계 논의 초기에 CDC 및 초기화 전략을 포함시키며, 이를 “실제 논리”가 완료된 후의 정리 단계가 아닌 설계 아키텍처의 일부로 다룹니다.
이 문제는 일반적입니다. 왜냐하면 배치 및 경로가 넷리스트 구조 변화에 날카롭게 반응하기 때문입니다. 기능적 변화가 사소해 보일 때에도 말입니다.
• 넷리스트 민감도: 작은 리팩토링이 패킹, 배치 결정 및 라우팅 혼잡을 변경할 수 있습니다.
• 제약 드리프트: 작은 XDC 변경(또는 누락된 커버리지)은 타이밍 변동을 증폭할 수 있습니다.
• 완화 습관: 점진적 구현, 선택적 계층 보존 및 안정적인 제약.
팀이 이러한 완화 습관을 채택할 때, 반복은 보다 예측 가능하게 느껴지는 경향이 있으며, 이는 타이밍을 다시 깨뜨리는 것에 대한 두려움 때문에 설계를 조기에 동결하려는 유혹을 줄입니다.
라이센스 고려 사항
프로젝트가 장치 커버리지 한계에 부딪히거나 특정 워크플로우에 필요한 고급 기능이 필요할 때 라이센스는 대화의 주제가 되는 경향이 있습니다.
• 표준: 종종 진입 및 중급 학습 보드와 기본 흐름과 일치합니다.
• 기업: 종종 더 광범위한 장치 지원 및 고급 기능과 일치합니다.
팀의 경우, 라이센스 서버에 의해 지원되는 플로팅 라이센스가 노드 잠금 라이센스보다 확장하는 데 자주 더 용이합니다. 특히 빌드가 공유 머신, 전용 빌드 서버 또는 CI 러너에서 실행될 때 더욱 그렇습니다. 많은 팀은 장치 로드맵에 라이센스를 조기에 정렬하기를 선호하며, 이는 장치 전환이 이미 비용이 많이 들고 정치적으로 어려울 때 라이센스 서프라이즈가 나타나는 경향이 있기 때문입니다.
일관된 엔지니어링 루프는 단일 똑똑한 최적화보다 안정적인 진행을 예측하는 경향이 있다: 제약 조건을 현실에 맞게 정렬하고, 보고서를 정기적으로 읽고(원하지 않더라도), 증상을 잠재우는 대신 근본 원인을 수정하며, 빌드를 재현 가능하게 유지한다. 이 루프가 확립되면, Vivado는 블랙 박스처럼 느껴지지 않고 계기판처럼 느껴지며, 타이밍 클로저는 마지막 순간의 긴장감에서 팀이 의도적으로 관리할 수 있는 것으로 변화한다.
자일링스 포트폴리오 및 생태계

자일링스 장치 중에서 선택하는 것은 시작점이 주변 통합(프로세서, 메모리 인터페이스, 부트 경로 및 보드 수준의 종속성)일 때 더 원활하게 진행되는 경향이 있으며, 단순히 원시 LUT 총합의 비교만으로는 이루어지지 않는다. 이러한 프레임은 일반적으로 실제 일정과 실제 위험이 나타나는 방식과 일치한다.
이산 FPGA는 팀이 보드 아키텍처에 대한 완전한 소유권을 원하고 작업 부하가 최소한의 소프트웨어 표면 영역으로 결정론적 하드웨어 동작을 지향할 때 적합하다. Zynq 클래스 SoC는 설계가 가속화 논리 가까이에 위치한 CPU에서 이점을 얻을 때 적합하며, 제어 및 데이터 경로가 보드를 다중 칩 협상으로 전환하지 않고 함께 발전할 수 있다. Kria SOM 스타일 모듈은 빠르게 이동하고 컴퓨팅, 메모리 및 부트 저장소를 사전 검사된 빌딩 블록으로 간주함으로써 보드 시작 불확실성을 제한할 계획일 때 적합하다.
이산 FPGA는 다음과 같은 경우에 적합하다:
• 최대 보드 디자인 제어
• 제한된 소프트웨어 종속성을 가진 결정론적 파이프라인
Zynq SoC는 다음과 같은 경우에 적합하다:
• 긴밀한 CPU+가속기 결합
• 하나의 장치에서 통합 컴퓨팅/제어
• 반복적인 HW/SW 발전
Kria SOM은 다음과 같은 경우에 적합하다:
• 제품 출시 시간 단축
• 검증된 컴퓨팅 하위 시스템을 사용하여 보드 수준 노출 감소
일반 FPGA는 타이밍 클로저 압력, 비정상적인 I/O 요구사항 또는 고정 기능 하드웨어로서 가장 잘 작동하는 스트리밍 파이프라인으로 인해 문제를 주도할 때 적합하다. 예측 가능한 대기 시간과 구조화된 데이터 경로는 일반적으로 제어, 검증 및 디버깅을 개선하며, 특히 아키텍처가 잘 조직되어 있을 때 더욱 그렇다.
독립형 장치는 다음과 같은 경우에 자주 나타난다:
• 센서 인터페이싱
• 모터 제어
• 중간 속도의 패킷 처리
• 프로토콜 브리징
현장에서 반복적으로 발생하는 불만의 원인은 RTL 자체가 아니라 조용히 도착하여 주요 경로를 지배하는 주변 보드 의무이다. 전원 레일, 구성 및 부트 전략, 클럭 생성, 외부 메모리 레이아웃(존재할 경우), 디버그 접근은 전체 제품을 형성하는 제약 사항으로 변할 수 있다. 실용적인 경험 법칙 중 하나는 외부 메모리 스토리어가 단순하고 고속 트랜시버의 수가 적을수록 독립형 FPGA 경험이 더 만족스러워진다는 것이다. 외부 DDR 및 다단계 부트 흐름이 불가피해지면 SoC나 모듈의 통합 매력이 기능처럼 느껴지기보다는 더 많은 구원처럼 느껴지기 시작한다.
비용 최적화된 패밀리는 일반적으로 제한된 전력 예산 하에 LUT, BRAM 및 DSP의 측정된 혼합을 목표로 한다. 그들은 엔지니어링 팀이 극단적인 인터페이스와 관련된 보드 및 열세금을 지불하지 않고도 존중할 수 있는 능력을 원할 때 제품에 많이 나타난다.
일반적인 유착 지점은 다음과 같다:
• 내장 제어
• 중간 범위 I/O 집합
• 중간 속도 신호 처리
장점은 단위 가격 뿐만 아니라, 팀은 이러한 부품이 공격적인 히트싱크에 의존하지 않고도 열 한계를 유지하는 것을 더 쉽게 만든다는 점을 높이 평가할 수 있으며, PCB가 고속 레이아웃 프로젝트로 격상되는 것을 방지할 수 있다. 동시에 현장 빌드는 약간 불편한 교훈을 정기적으로 가르친다: 저비용 장치가 늦은 단계의 설계 타협을 강요하면 총 지출이 증가할 수 있다. 타이밍 여유가 얇고 작은 조정, I/O 표준 변경, 클럭 라우팅 조정, 바닥 계획 변경이 검증 소모와 일정 불안을 초래할 수 있다. 이러한 장치의 경우, 팀은 일반적으로 계획이 늦은 마이크로 최적화로 구출되기를 바라는 대신에 클럭 도메인 계획, CDC 전략 및 리셋 동작을 조기에 정리함으로써 시간을 절약한다.
Zynq SoC
Zynq 장치는 ARM 처리와 프로그래머블 논리를 결합하여 설계가 제어-plane 소프트웨어와 데이터-plane 가속으로 분리될 수 있게 한다. 이는 많은 제품 팀에게 자연스럽게 느껴지는 방식이다. 이는 단순히 편리함을 향상시키는 것 이상으로, 작업 흐름을 재구성한다. 팀은 기능적인 신뢰를 위해 소프트웨어 우선 참조로 시작한 후, 처리량 및 대기 시간 요구 사항이 덜 협상 가능해짐에 따라 핫 경로를 하드웨어로 마이그레이션할 수 있다.
잘 나가는 배포에서 CPU는 하드웨어를 “대체”하는 경우가 드물며, 제품을 안정적으로 유지하는 경향이 있습니다. 프로세서는 종종 구성, 텔레메트리, 현장 업그레이드, 보안 정책, 엣지 연결성을 처리하는 반면, 패브릭은 결정론적 파이프라인을 실행합니다. 이러한 분리는 유지보수자에게 감정적으로 안심이 되는 요소가 됩니다: 소프트웨어는 변화를 흡수하고, 하드웨어는 안정성을 유지하며, 릴리스는 도박처럼 느껴지지 않습니다.
CPU는 일반적으로 다음을 포함합니다:
• 구성
• 텔레메트리
• 업그레이드
• 보안 정책
• 엣지 연결성
패브릭은 일반적으로 다음을 포함합니다:
• 결정론적 스트리밍 파이프라인
• 안정적인 가속기
• 지연 민감한 데이터 경로
컴퓨트 밀도가 증가하고 인터페이스의 요구가 커짐에 따라, Zynq UltraScale+ 스타일의 부품은 CPU 코어, DDR 컨트롤러 및 고대역폭 인터커넥트를 패브릭에 더 가깝게 끌어들여 보드 및 시스템 복잡성을 줄입니다. 이는 실시간 결정론과 유능한 소프트웨어 환경이 모두 필요한 설계에서 매력적이 되며, 특히 작업 부하가 단일 깨끗한 커널이 아닌 혼합일 때 더욱 그렇습니다.
자주 사용되는 사례는 다음과 같습니다:
• 엣지 분석
• 다중 센서 융합
• 혼합 실시간 및 AI 파이프라인
숙련된 팀이 존중하는 세부 사항은 “더 많은 패브릭”이 자동적으로 “더 많은 성능”으로 전환되지 않는다는 것입니다. 프로젝트는 종종 DSP나 LUT가 부족하기 전에 메모리 대역폭의 한계에 도달합니다. DMA 토폴로지, 버퍼링 전략 및 캐시 일관성 기대를 조기에 결정한 설계는 데이터 이동 결정을 늦게 통합한 설계보다 쓰레시가 적고 안정적인 성능에 도달하는 경향이 있습니다.
파르티셔닝은 어떤 것이 가속될 수 있느냐에 관한 것이 아니라, 검증 노력, 드라이버 및 런타임 복잡성, 논리가 얼마나 자주 변경될 것으로 예상되는지에 따라 가속이 효과를 낼 것인가에 관한 것입니다. 팀은 종종 여기에서 줄다리기를 느낍니다: 너무 많은 것을 하드웨어로 밀어 넣으면 반복 속도가 느려질 수 있고, CPU에 너무 많은 것을 맡기면 처리량 목표가 영원히 거의 도달할 수 없습니다.
예상보다 CPU에 오래 머무는 작업 부하에는 다음이 포함됩니다:
• 빠르게 변화하는 논리
• 복잡한 파싱 중심의 동작
• 빠른 반복 주기를 가진 기능
자주 조기 패브릭 가속의 보상을 받는 작업 부하에는 다음이 포함됩니다:
• 안정적인 알고리즘
• 컴퓨트 밀도가 높은 커널
• 스트리밍 친화적인 데이터 경로
실용적인 패턴은 간단한 DMA 루프백과 최소한의 가속기를 포함한 작은 종단 간 슬라이스로 시작한 다음, 전체 기능 세트를 구축하는 것입니다. 제한된 프로토타입은 종종 늦고 비용이 많이 드는 통합 문제를 드러내는 경향이 있습니다: 인터럽트 동작, 버퍼 정렬, 캐시 유지 비용, 지속적인 부하에서만 나타나는 처리량 한계.
Kria SOM 및 모듈 스타일 플랫폼
Kria SOM은 컴퓨트, 메모리, 부팅 저장소를 준비된 서브시스템으로 패키징하여 보드 올리기에서 응용 프로그램 엔지니어링으로 노력을 전환합니다. 팀은 종종 이 접근 방식을 선호하는데, 이는 불확실성을 포함하기 때문입니다: 신호 무결성, DDR 라우팅, 전원 순서 및 부팅 신뢰성이 이미 검증되어 있어 초기 데모가 덜 취약하게 느껴지고 계획이 덜 투기적으로 느껴질 수 있습니다.
이 접근 방식은 차별화가 알고리즘, I/O 토폴로지 및 배포 신뢰성에 존재할 때 특히 잘 작동하는 경향이 있습니다. 또한 팀 간 마찰을 줄일 수 있습니다: 하드웨어, 펌웨어 및 응용 프로그램 작업이 “올리기에 의해 차단됨” 순간이 적어 병렬로 진행될 수 있습니다.
검증된 SOM 통합은 일반적으로 다음을 포함합니다:
• 신호 무결성
• DDR 라우팅
• 전원 순서
• 부팅 신뢰성
팀은 다음에 노력을 재조정할 수 있습니다:
• 캐리어 보드 차별화
• 펌웨어 통합
• 응용 프로그램 동작
• 배포 강화
SOM은 일반적으로 완전히 맞춤형 보드보다 단위당 비용이 더 높지만, 일정이 촉박하거나 제조 수율 위험이 불편할 때 총 프로그램 비용이 여전히 감소할 수 있습니다. 덜 명백한 이점은 생애 주기 예측 가능성입니다: 모듈을 사용하면 때때로 컴퓨트가 제품 변형 간의 교환 가능한 요소로 취급될 수 있어 요구 사항이 중간에 변경될 때 재설계 반복을 줄일 수 있습니다.
가장 진정시키는 단계는 SOM의 열 여유, I/O 노출 및 메모리 대역폭이 실제로 의도된 작업 부하와 일치하는지 조기에 검증하는 것입니다. 사양 시트의 읽기를 신뢰하기보다는 말입니다. 만약 애플리케이션의 대역폭이 한정된다면, 후반 단계의 조정은 잠긴 문을 밀어붙이는 것처럼 느껴지는 경향이 있으며, 가속기 수요와 모듈의 메모리 서브시스템 사이의 불일치가 단순히 지배하게 됩니다.
초기 적합성 검사는 일반적으로 다음을 포함합니다:
• 열 외피
• 노출된 I/O
• 지속적인 메모리 대역폭 대 작업 부하 수요
생태계에서의 AI 배포
Vitis AI는 훈련된 모델을 FPGA 기반 추론 설계로 변환하는 데 도움을 주며, 대개 INT8과 같은 저정밀 형식을 사용하고 이를 DPU 스타일 아키텍처에 맞게 컴파일합니다. 이를 통해 모델이 FPGA 플랫폼에서 작동할 수 있는지를 신속하게 확인할 수 있습니다. 그러나 실제 성능은 주변 시스템 설계, 특히 데이터 이동 및 메모리 처리에 크게 의존하는 경우가 많습니다.
엔드 투 엔드 처리량은 일반적으로 시스템이 DPU에 얼마나 일관되게 데이터를 공급할 수 있는지에 의해 결정됩니다. 배치 전략, 텐서 레이아웃, DMA 스케줄링, 더블 버퍼링 및 메모리 배치는 종종 제공되는 FPS를 연산 수치보다 더 많이 결정합니다. DPU를 정적인 스트리밍 소비자처럼 취급하고 신중하게 배치된 버퍼를 사용하는 팀은 인상적인 이론적 TOPS와 저조한 시스템 수준 결과 사이에서 발생하는 일반적인 실망을 피하는 경향이 있습니다.
성능 조정 요소에는 일반적으로 다음이 포함됩니다:
• 배치 전략
• 텐서 레이아웃
• DMA 스케줄링
• 더블 버퍼링
• 메모리 배치
배포 시, 사소한 구현 선택이 실험실 마이크로 벤치마크에서 예측하기 어려운 방식으로 누적될 수 있습니다. 잘못 정렬된 버퍼는 조용히 유효 대역폭을 감소시킬 수 있습니다. 과도한 캐시 유지 관리는 CPU 시간을 소모하고 지터를 발생시킬 수 있습니다. 복사 중심의 파이프라인은 양자화로 얻은 많은 이점을 지울 수 있습니다. 근본적인 접근 방식은 각 경계에서 대역폭과 지연 시간을 측정한 다음 현재 가장 타이트한 경계에 집중하는 것입니다.
유용한 측정 경계에는 다음이 포함됩니다:
• 센서에서 DDR로
• DDR에서 가속기로
• 가속기에서 후처리로
도움이 되는 정신 모델은 AI 파이프라인을 제약된 흐름 네트워크로 보는 것입니다. 이를 통해 장치 선택은 가장 큰 연산 수치를 추구하는 것이 아니라 주요 병목 현상을 완화하고 파이프라인의 동작을 예측 가능하게 유지하는 옵션을 선택하는 것에 더 중점을 두게 됩니다.
생태계 및 지원
Xilinx 생태계는 실리콘을 넘어 팀이 원활하게 움직일 수 있도록 하는 주변 지원으로 확장됩니다: 도구 체인, IP, 참조 설계, 파트너 보드 및 교육 자료. 학술 환경에서는 대학교 프로그램이 반복되는 설정의 어려움, 도구 접근성, 보드 가용성, 실험실 구조를 줄여 주기 때문에 종종 감사받습니다. 이로 인해 초기 진행이 실제 공학을 배우는 데 더 이상 환경 문제로 정체되는 일이 적어집니다.
생태계 구성 요소는 다음을 포함합니다:
• 도구 체인 (Vivado, Vitis)
• IP 카탈로그
• 참조 설계
• 파트너 보드
• 교육 프로그램
• 대학교 프로그램 자료
온보딩 마찰이 줄어들면, 학습자는 전문 작업으로 직접 전환되는 습관에 에너지를 사용할 수 있습니다: 타이밍 종료 루틴, 파이프라인 규율, 검증 전략 및 하드웨어/소프트웨어 공동 설계 판단. 이러한 기술은 통합 과정에서 더욱 그 가치를 드러내며, 그 결과는 고립된 커널 벤치마크보다 반복 속도와 시스템 응집력에 의해 형성됩니다.
전이 가능한 기술에는 다음이 포함됩니다:
• 타이밍 종료 습관
• 파이프라인 규율
• 검증 전략
• 하드웨어/소프트웨어 공동 설계
라인업 전반에서 일관되게 유지되는 선택 원칙
신뢰할 수 있는 선택 접근 방식은 마케팅 계층이 아니라 시스템 제약에서 시작됩니다. 팀은 운영 목표와 프로젝트 현실을 미리 적어두면 이리온 감이 더 선명해지기 때문에, 그들의 특정 프로그램에 대한 불확실성을 줄이는 통합 수준, FPGA, Zynq SoC 또는 SOM을 선택하는 경향이 있습니다. 이렇게 되면 몇 달 후 통합 및 반복 속도가 서류상의 부품 비교보다 더 중요한 시점에 보다 나은 선택을 하게 됩니다.
초기에 정의해야 할 제약 사항은 다음과 같습니다:
• 지연 시간 목표
• 지속적인 대역폭 요구
• 인터페이스 요구 사항
• 열 한계
• 업데이트 주기
• 검증 예산
많은 프로그램에서 데이터 이동을 간단하게 유지하고 개발 루프를 타이트하게 만드는 옵션이 처음에는 단가가 가장 매력적이지 않더라도 시간이 지나면서 가장 잘 보존됩니다.
결론
각 프로젝트가 안정적이고 반복 가능한 프로세스를 따를 때 Xilinx FPGA 설계를 배우는 것이 더 쉬워집니다. 강력한 결과는 깔끔한 HDL, 올바른 제약, 신중한 타이밍 검사, 시뮬레이션 및 실제 하드웨어 검증에 달려 있습니다. 간단한 디자인으로 시작하고 좋은 디버깅 습관을 함양함으로써 초보자들은 더 고급 디지털 시스템을 위한 신뢰할 수 있는 FPGA 기술을 개발할 수 있습니다.
자주 묻는 질문 [FAQ]
1. FPGA 초보자들이 HDL 코드가 시뮬레이션에서 논리적으로 올바르게 보일 때에도 종종 어려움을 겪는 이유는 무엇인가요?
많은 초기 FPGA 문제는 RTL 자체에서 발생하는 것이 아니라 시뮬레이션 가정과 실제 하드웨어 동작 사이의 차이로 인해 발생합니다. 시뮬레이션은 일반적으로 클락 제약, 리셋 타이밍, I/O 표준, 메타 안정성 및 타이밍 마감과 관련된 문제를 숨깁니다. 설계가 완벽하게 시뮬레이션될 수 있지만 FPGA 도구가 클락을 다르게 해석하거나 제약이 불완전하거나 비동기 입력이 잘못 처리되었기 때문에 하드웨어에서 실패할 수 있습니다.
2. 타이밍 제약이 최종 최적화 단계가 아닌 FPGA 설계의 핵심 부분으로 간주되는 이유는 무엇인가요?
타이밍 제약은 FPGA 도구가 클락, I/O 타이밍 관계, 생성된 클락 및 비동기 도메인을 해석하는 방식을 정의합니다. 정확한 제약이 없으면 Vivado가 잘못된 가정을 사용하여 설계를 최적화하여 오해를 일으키는 타이밍 보고서 및 불안정한 하드웨어 동작으로 이어질 수 있습니다. 논리 자체가 올바르더라도 타이밍이 제대로 선언되지 않았거나 I/O 타이밍이 무시되거나 예외가 너무 광범위하게 적용되어 많은 FPGA 실패가 발생합니다. 실제로 제약은 설계 의도의 공식적인 설명으로 작용하여 도구가 실제 전기 동작과 일치하는 하드웨어를 구축할 수 있도록 합니다.
3. 왜 FPGA 디버깅에 종종 시뮬레이션과 ILA와 같은 온칩 도구가 필요합니까?
시뮬레이션은 기능적 버그를 감지하는 데 매우 효과적이지만 지터, 비동기 입력, 보드 수준 지연, 메타 안정성 및 전원 켜짐 변Variation와 같은 실제 하드웨어 효과를 완전히 재현할 수는 없습니다. 통합 논리 분석기(ILA)와 같은 온칩 디버깅 도구는 시스템이 실제 조건에서 작동하는 동안 내부 FPGA 신호에 대한 가시성을 제공합니다. 이를 통해 장치 내부에서 실제 상태 전환, FIFO 동작, 핸드셰이크 및 타이밍 관계를 직접 캡처할 수 있습니다. 시뮬레이션과 ILA 디버깅을 결합하면 하드웨어가 예상 동작과 왜 다르게 동작하는지에 대한 보다 완전한 이해를 제공합니다.
4. 왜 경험이 많은 FPGA 엔지니어는 끊임없이 변화하는 프로젝트 설정보다 규칙적이고 반복 가능한 워크플로를 선호합니까?
반복 가능한 워크플로는 불확실성을 줄이고 실패를 쉽게 격리할 수 있게 해줍니다. 동일한 개발 보드, 클락 구조, 리셋 전략 및 프로젝트 템플릿을 사용하면 엔지니어는 환경 자체를 반복적으로 디버깅하지 않고 개발 중인 논리에 집중할 수 있습니다. FPGA 프로젝트에는 제약, 클락, 합성 동작 및 보드 수준 구성 등 많은 상호 작용하는 변수가 포함됩니다. 너무 많은 변수가 동시에 변경되면 디버깅이 예측할 수 없게 되고 감정적으로 소모됩니다. 안정적인 워크플로는 변경 사항을 알 수 없는 환경 차이가 아닌 특정 설계 결정에 추적할 수 있어 신뢰를 향상시킵니다.
5. FPGA 하드웨어 설계가 전통적인 소프트웨어 프로그래밍과 근본적으로 다른 이유는 무엇입니까?
소프트웨어는 명령을 순차적으로 실행하지만 FPGA 하드웨어는 동시에 실행되는 동시 논리 구조를 통해 작동합니다. HDL은 절차적 실행 흐름이 아닌 물리적 하드웨어 동작을 설명합니다. 초보자들은 종종 소프트웨어와 유사한 동작을 기대한 후 여러 하드웨어 블록이 동일한 클락 엣지에서 병렬로 반응할 때 혼란스러워합니다. 따라서 FPGA 설계는 단순한 명령 순서보다 파이프라인, 타이밍 관계, 동기화, 리소스 매핑 및 클락 도메인 동작을 강조합니다. 동시성을 이해하는 것은 FPGA 엔지니어링에서 가장 중요한 사고 전환 중 하나입니다.
6. 작은 RTL 변화가 FPGA 프로젝트에서 갑자기 주요 타이밍 마감 문제를 일으킬 수 있는 이유는 무엇입니까?
FPGA 타이밍 동작은 배치, 라우팅 혼잡, 팬아웃, 클락 관계 및 물리적 리소스 사용에 크게 의존합니다. 작은 RTL 수정조차도 합성 및 라우팅 도구가 장치 전반에 걸쳐 논리를 매핑하는 방식을 변경할 수 있습니다. 겉보기에는 해가 없어 보이는 변경이 라우팅 압력을 증가시키거나 조합 경로를 길게 하거나 배치 결정을 영향을 미쳐 타이밍 여유를 유의미하게 줄이게 할 수 있습니다. 이러한 민감도는 활용도가 증가함에 따라 더 심각해지며 특히 설계가 라우팅 또는 클락 한계에 가까워질 때 더욱 그렇습니다.
7. 왜 FPGA 프로젝트는 RTL 복잡성만으로는 아니라 보드 수준 현실에 의해 자주 제한되나요?
FPGA 시스템이 성장함에 따라 전원 시퀀싱, DDR 레이아웃, 클락 생성, 열 거동, 신호 무결성 및 트랜시버 라우팅과 관련된 문제들이 종종 개발 시간을 지배합니다. RTL은 올바르게 작동할 수 있으나 주변 하드웨어 인프라가 불안정성이나 통합 실패를 초래할 수 있습니다. 엔지니어들은 종종 보드 설계 결정, 리셋 시퀀싱 및 메모리 인터페이스 동작이 HDL 자체보다 전체 프로젝트의 성공에 더 큰 영향을 미친다는 것을 발견합니다. 이는 외부 DDR 메모리 및 SERDES 인터페이스를 사용하는 고속 시스템에서 특히 그렇습니다.
8. 왜 많은 FPGA 팀이 FPGA 하드웨어 자체만큼 도구 체인을 심각하게 평가합니까?
FPGA 툴체인은 컴파일 시간, 타이밍 클로저 안정성, 디버깅 효율성, CI 통합 및 전반적인 엔지니어링 생산성에 직접적인 영향을 미칩니다. 느리거나 일관되지 않은 구현 결과는 반복 시간과 일정 압박을 극적으로 증가시킬 수 있습니다. 팀은 플랫폼에 의사결정을 내리기 전에 합성 품질, 타이밍 보고서 명확성, 디버그 계측 및 재현성을 평가하는 경우가 많습니다. 실제 개발 환경에서는 예측 가능한 빌드와 안정적인 타이밍 클로저가 종종 개별 헤드라인 FPGA 사양보다 더 중요합니다.
9. Zynq SoC와 Kria SOM 플랫폼은 독립형 FPGA에 비해 통합 복잡성을 어떻게 줄이는가?
Zynq SoC는 ARM 프로세서와 프로그래머블 논리를 하나의 장치에 결합하여 소프트웨어와 하드웨어 가속기 간의 통신을 단순화합니다. Kria SOM은 메모리, 부팅 저장소, 전원 시퀀싱 및 검증된 하드웨어를 사전 검증된 모듈로 통합함으로써 한 걸음 더 나아갑니다. 이러한 접근 방식은 DDR 라우팅, 부팅 신뢰성, 전원 공급 설계 및 보드 올리기와 관련된 위험을 줄입니다. 그 결과, 팀은 저수준 하드웨어 통합 문제보다는 애플리케이션 동작에 더 집중할 수 있습니다.
10. 성공적인 FPGA 기반 AI 배포가 단순한 가속기 성능보다 데이터 이동에 크게 의존하는 이유는 무엇인가?
DPU와 같은 AI 가속기는 이론적으로 높은 계산 처리량을 제공할 수 있지만, 실제 성능은 종종 메모리 대역폭, DMA 스케줄링, 버퍼 관리 및 텐서 이동 효율성에 의해 제한됩니다. 최적화되지 않은 데이터 파이프라인은 가속기를 기아 상태로 만들고 강력한 계산 능력에도 불구하고 실제 FPS를 극적으로 줄일 수 있습니다. 성공적인 FPGA AI 시스템은 따라서 더블 버퍼링, DMA 토폴로지, 배치 전략, 메모리 배치 및 센서, DDR 메모리, 가속기 및 후처리 단계 간의 지속적인 데이터 흐름에 크게 집중합니다.
관련 블로그
-
백만, 10 억, 조만에 몇 개의 0이 있습니까?
![백만, 10 억, 조만에 몇 개의 0이 있습니까?]()
2024년7월29일
백만은 10을 나타냅니다6, 일상적인 품목이나 연봉과 비교할 때 쉽게 파악할 수있는 수치. 10 억, 10에 해당합니다9, 대규모 금융 거래 또는 국가 GDP를 포함하... -
IRLZ44N MOSFET 데이터 시트, 회로, 동등한, 핀아웃
![IRLZ44N MOSFET 데이터 시트, 회로, 동등한, 핀아웃]()
2024년8월28일
IRLZ44N은 널리 사용되는 N- 채널 전력 MOSFET입니다.우수한 스위칭 기능으로 유명한이 제품은 특히 전력 전자 및 전압 조절에서 수많은 응용 분야에 매우 적합... -
배터리 온도가 너무 낮아 충전이 중단되었습니다.고치는 방법?
![배터리 온도가 너무 낮아 충전이 중단되었습니다.고치는 방법?]()
2024년10월6일
휴대 전화 배터리 충전 문제는 일반적이지만 효과적으로 관리 할 수 있습니다.스마트 폰 배터리가 특정 온도 범위 내에서 가장 잘 작동하기 때문에 온도는 ... -
BC547 트랜지스터 종합 가이드
![BC547 트랜지스터 종합 가이드]()
2024년7월4일
BC547 트랜지스터는 기본 신호 증폭기에서 복잡한 발진기 회로 및 전원 관리 시스템에 이르기까지 다양한 전자 응용 분야에서 일반적으로 사용됩니다.저렴한 비... -
SCR에 대한 포괄적 인 가이드 (실리콘 제어 정류기)
![SCR에 대한 포괄적 인 가이드 (실리콘 제어 정류기)]()
2024년4월22일
실리콘 제어 정류기 (SCR) 또는 사이리스터는 성능과 신뢰성으로 인해 전력 전자 기술에서 중추적 인 역할을합니다.이 기사는 사이리스터의 구조, 작동 및 사용... -
LR621, SR621SW, 364, AG1 배터리 등가 및 교체
![LR621, SR621SW, 364, AG1 배터리 등가 및 교체]()
2024년7월15일
LR621 및 SR621SW 버튼 배터리는 시계, 작은 장난감, 계산기 및 원격 키와 같은 소형 전자 장치에서 널리 퍼져 있습니다.여러 제조업체 가이 배터리를 생산하여 ... -
멀티플렉서에 대한 완전한 가이드 및 디지털 시스템에서의 역할
![멀티플렉서에 대한 완전한 가이드 및 디지털 시스템에서의 역할]()
2025년9월20일
멀티플렉서는 이진 로직 및 제어 신호를 사용하여 다중 입력 신호를 단일 출력 라인으로 전달하도록 설계된 디지털 시스템의 구성 요소입니다.회로 설계를 단순... -
OP-AMP 회로의 기본 사항
![OP-AMP 회로의 기본 사항]()
2023년12월28일
복잡한 전자 제품의 세계에서, 그 신비로의 여행은 우리를 항상 절묘하고 복잡한 회로 구성 요소 만화경으로 이끌어줍니다.이 영역의 핵심은 OP AMP (Operationa... -
NMOS 및 PMOS 차이 및 응용 프로그램 비교
![NMOS 및 PMOS 차이 및 응용 프로그램 비교]()
2024년11월15일
NMOS와 PMOS 트랜지스터의 차이를 이해하는 것은 효율적인 회로 설계에 중요합니다.NMOS (N- 타입 금속-산화물-세미 컨덕터) 및 PMOS (P- 타입 금속-산화물 세미... -
CR2450 대 CR2032 비교 : 알아야 할 모든 것
![CR2450 대 CR2032 비교 : 알아야 할 모든 것]()
2025년9월15일
CR2450 및 CR2032와 같은 버튼 배터리는 시계 및 리모컨에서 의료 및 산업용 장치에 이르기까지 많은 일상적인 전자 장치에 전력을 공급합니다.작지만이 동...










핫 파트
- TPSE107M010R0125
- MIC5319-3.3YD5-TR
- PI3HDMI412FT-BBE
- MM1293AJBE
- DM74ALS151M
- SM4152
- FDN340P
- MPC860TCVR66D4
- XC95144-15PQ160C
- IDT7024L35J
- S1R72U16B08E200
- L4973D3.3-TR
- M41T81M6E
- MAX14599EEWV+T
- MX29SL802CBXHI-90G
- SP3220EEA
- DS1220Y-200+
- CY7C1480BV33-250BZI
- GRM1885C1H3R0BA01J
- ISP1161A1BDTM
- GRM1535C1HR60BDD5D
- MICRF600Z
- AD5648ARUZ-2
- ZL30406QGG1
- ERA-6AEB101V
- DG509BEY
- RT0402BRD073K9L
- ZR39660BGCG-B1
- 0805ZC222KAT2A
- M68AW127BM70NK6T
- C2012CH1H472K060AA
- THS6072IDGNRG4
- T491D106K050AT7027
- VE-JW3-MY
- TPS543B20RVFR
- VE-J72-EZ
- T491C476M006ZTZ012
- GS8644Z36B-200
- VSC8247XJB-01
- XC3S50-VQG100E
- HI3110RQC
- L610Q431
- SP6620HP
- TMS320VC33PGE-150
- IS43TR16640C-125JBLI
- IPB117N20NFD
- GDH04STR04
- COS721TR
- SEMiX453GD17E4c
- FH8065301685964Q